Overview of XPath |
|
Process Platform supports all the functions in XPATH 1.0 specifications as recommended by W3C and specifc XPath 2.0 functions supported by Process Platform are specified here |
Understanding XPath
XPath is one of the most useful features while using XML elements. Its primary purpose is to address specific parts (nodes) of an XML document. In simple terms, it functions more like the SQL 'select' statement for databases. As the name suggests, it uses path notation as in URL(s) for navigating through the hierarchical structure of an XML document and to identify the nodes in it. This process is similar to the path expressions of your file system.
Additionally, XPath also provides basic facilities for manipulating strings, numbers, and boolean values. It operates on the abstract, logical structure of an XML document, rather than its surface syntax and uses a compact, non-XML syntax to identify particular parts of XML documents within URI(s) and XML attribute values.
XPath lets you write expressions that refer to the document's specific elements with respect to their position (first person element, the seventh child element of the third person element, and so on) including all xml-stylesheet processing instructions in the document's prolog.
XPath is a specification from W3C ( http://www.w3.org ). For more details on the specification as recommended by W3C, refer to http://www.w3.org/TR/xpath.
Architecture of XPath
The following diagram demonstrates the way XPath processes an XML document.
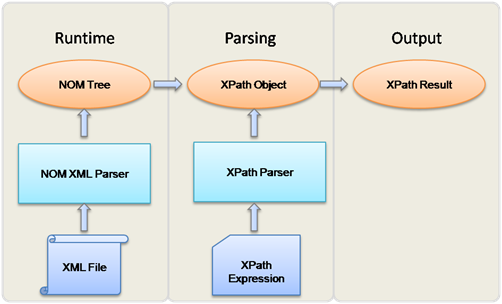
XPath Concepts
To understand XPath, you must understand the concepts of XPath. The following are the concepts of XPath:
- Understanding XPath Expressions
- Defining XPath Expressions
- XPath Parser, XPath Object, and XPath Output
You can use XPath API(s) that are implemented in Process Platform. For more information on XPath API(s), refer to Using XPath API(s).
Benefits of Using XPath
XPath is designed for XML documents. It provides a single syntax that you can use for queries, addressing, and patterns. XPath is concise, simple, and powerful. The benefits of XPath are listed below:
- Queries are compact, easy to type and read, and are easily parsed.
- Syntax is simple for the most common cases that are simple in nature.
- Query strings are easily embedded in programs, scripts, and XML or HTML attributes.
- Enables specifying any path that can occur in an XML document and any set of conditions for the nodes in the path.
- Enables uniquely identifying any node in an XML document.
- Queries return any number of results, including zero, but not repeated nodes.
- Query conditions can be evaluated at any level of a document and are not expected to navigate from the top node of a document.
- Enables usage in many contexts. It is used for providing links to nodes, for searching repositories, and for many other applications.
Invoking java functions using XPath
Java function can be invoked through a XPath to facilitate implementation of custom logic
package com.cordys.xml.nom;
import com.eibus.xml.xpath.XPath;
import com.eibus.xml.xpath.XPathResult;
public class XPathExample {
public static String getHelloString(String arg) {
return "Hello " + arg;
}
public static void main(String[] args) {
XPath xpath = XPath
.getXPathInstance("com.cordys.xml.nom.SampleXPath.getHelloString(\"World\")");
XPathResult result = xpath.evaluate(null);
System.out.println(result.getStringResult());
}
}
Hello World